入力や出力を見ずにプロンプトを調整する
- Al Roborol
- Fun , Insight
- 2025年10月28日
Table of Contents
入力と出力を見ずにプロンプトを調整することは可能か?
入力と出力を知らずにプロンプトを調整するというのは、質問を知らずに正しい答えを書き下すような愚かな話に聞こえるかもしれない。
私自身も必要性に疑問を持っていましたが、ある時点で事業部内のすべてのチームがそれぞれ独自の金庫(vault)にデータを保存しており、同じ事業部内の他チームもそのデータにアクセスできないという状況に直面しました。そこで AI ワークフローやアプリを作るというのはまさに、質問を見ることなく答えを出すことに相当します。自動車のような製造業では、このような組織形態がよく見られます。
データは閉じているが、目標は開かれている
幸いにも、製造業ではデータが閉じていても共通の開かれた目標が存在します。サプライチェーンでは在庫回転率、運用では平均修理時間(MTTR)、製造ではタクトタイム、研究開発では市場投入までの時間などがその例です。
こうした共通の目標があることで、データを見ずに製造業に強化学習(RL)を適用することが可能になります。RL はポリシーモデル、目標、そしてジム(gym)で構成されます。ジムはAIが住み、相互作用する世界です。ポリシーモデルはジムと継続的にやり取りして目標達成のための最適戦略を学び、ポリシーがジム内で目標を達成する最良の方法を見つけると学習は終了します。ジムの内部はトレーニング全体を通して隠蔽され、最小限の観測可能量のみが公開されます。
これが製造業にとっての解法そのものです。内部データがジム(AI が学習するための世界)の内部に相当します。適切な観測可能量と目標があれば、内部は常に隠したままで問題ありません。そしてこれらの目標は開かれており普遍的です。
実際にどうやるか
製造業でよくあるソフトウェア開発を例にとりましょう。AI を使ったドキュメント生成もそこで必要になります。違いは、ドキュメントを生成するための元となるコードが隠されている点だけです。
まず目標を定義します。ドキュメント生成には企業ごとに異なる戦略があるため多くの目標が考えられます。正しい答えを与えるのは難しいので、単純化のために「生成されたドキュメントがバグ修正に役立つかどうか」を目標にしましょう。悪くない目標です。
次にジムの定義です。
データについて知らないので、データ構造に関して仮定はできません。しかしデータはどこかに保存されており、GitHub(少なくとも Git)が選択肢となることが多いです。多くの場合、プルリクエスト(PR)がコードのレビューとマージに使われていると仮定するのは大きく外れていないでしょう。ここでは GitHub API を用いて PR を取得できると仮定します。実際のケースでは常にそうとは限らないため、開始前に顧客と十分に確認する必要があります。
PR をジムにするためには、データとの可能な相互作用と観測可能な出力を定義する必要があります。プログラマはパッチ(コード修正)を提出してコードとやり取りします。PR が検証済みの修正であることを考えると、実際の PR のパッチと生成されたパッチの類似度は良い出力指標になります。
最後にトレーニングの話です。これは大きな話題になります。高次元埋め込みを含む離散空間で最適解を探す数学を詳しく見たくはないでしょう。手短に言うと、ShinkaEvolve を使うことを推奨します。ShinkaEvolve は突然変異(mutation)で候補ポリシーをロバストかつ効率的に生成し、進化のようなフィルタリングで最適なものを選びます。適者生存です。
本当にうまくいくのか?
うますぎる話は信じがたいものですが、これは本当に機能します。
オープンなリポジトリ(元の設計が含まれる)で簡単なテストを実施し、RL モデルで生成したドキュメントの有無でパッチ類似度スコアを比較しました。対象リポジトリは https://github.com/pallets/click です。
この実験の背後にあるモデルは Copilot CLI のエージェントモードを有効にした gpt-5-mini です。おそらく今この場で使用しているモデルと同じでしょう。
スコアは 0.117 から 0.450 に上昇しました。精度は約4倍になりました。
スコアは 0〜1 の正規化された 3 つの成分で構成されます:
- file_score: 触れられたファイルパスの和集合上でのファイル毎のハンクリストの完全一致(厳密、順序依存)
- func_score: ハンクから抽出した変更された関数名のジャカード重複
- var_score: ハンクから抽出した変更された変数/代入名のジャカード重複
最終的な重み付けは次の通りです:
combined=0.5 * file_score + 0.35 * func_score + 0.15 * var_score
試してみたい方はこちらのコードを参照してください: https://github.com/alroborol/ShinkaEvolve-DocAgent
実験は何をするのか?
先に述べたように、この実験はコードを見ずにドキュメントを作成する AI を構築しようとするものです。ドキュメントはバグ修正に役立つなら良いとみなされます。
評価は計算資源の制約から、リポジトリの中の選ばれた 3 件の PR のみで行いました。
具体的には、チューニング対象の AI はドキュメント生成ワークフロー内の 4 つのプロンプトです。1 つはユニバーサルプロンプト、残り 3 つはワークフロー内の各プロセス向けのプロンプトです。
以下は進化前の実際の初期プロンプトです(コードブロックは原文のまま保持):
# EVOLVE-BLOCK-START
# System-level instruction: sent as the `system_msg` to the LLM client to
# establish role and global expectations for all queries in this module.
SYSTEM_MESSAGE = (
" "
)
# Summarization prompt: used to create concise, developer-facing documentation
# geared toward code review, focusing on purpose, APIs, error handling and edge
# cases. Use when summarizing selected files.
SUMMARIZE_DOC_PROMPT = (
"Summarize the document"
)
# Template for asking the LLM to select files from a rendered file-tree. The
# `{tree}` placeholder is replaced with the textual tree when calling the LLM.
SELECTION_PROMPT_TEMPLATE = (
"Given the project file tree below, pick files to check."
"eply ONLY with a JSON array of the "
"relative file paths you choose (no extra text).\n\n{tree}\n"
)
# Template for summarization calls: inject a summarization prompt plus the
# concatenated file contents into `{doc_prompt}` and `{files}` respectively.
SUMMARIZE_PROMPT_TEMPLATE = (
"{doc_prompt}\n\n{files}"
)
# EVOLVE-BLOCK-END
最終的なプロンプトは以下の通りです(要点は出力フォーマットの細化です。コードブロックは変更せずに保持):
# EVOLVE-BLOCK-START
# System-level instruction: sent as the `system_msg` to the LLM client to
# establish role and global expectations for all queries in this module.
# Strongly prefer machine-parseable outputs (JSON/unified-diff) and minimal,
# human-like edits that can be applied as patches. Do NOT include freeform
# commentary outside the required structured output.
SYSTEM_MESSAGE = (
"You are an expert software maintainer and reviewer. Produce concise, "
"patch-oriented developer documentation that directly supports creating and "
"applying fixes. Always return only the structured output requested by the "
"prompt (see below) with no extra explanation. Favor unified-diff snippets "
"for code edits, include clear tests-to-add, and provide short 'risk' and "
"'confidence' fields so downstream tooling can prioritize changes."
)
# Prompt used to create concise, developer-facing documentation geared toward
# producing fixes: the output MUST be valid JSON. For single-file summaries
# return an object; for multiple files return a single JSON object containing
# per-file entries. Each per-file entry should include:
# - path: relative file path
# - short_description: 1-2 sentence diagnosis
# - suggested_patch: unified-diff string OR a minimal step list (prefer diff)
# - tests: list of one-line test suggestions
# - risk: 'low'|'medium'|'high'
# - confidence: float between 0 and 1
SUMMARIZE_DOC_PROMPT = (
"Summarize the document(s) into a JSON object. For each file include: "
"path, short_description (1-2 sentences), suggested_patch (unified-diff preferred), "
"tests (list of one-line suggestions), risk ('low'|'medium'|'high'), and "
"confidence (0-1). Output must be valid JSON and nothing else."
)
# Top-level prompt used to request generation of docs + patches. The model MUST
# return a single JSON object with fields:
# - title, summary (<=120 chars), affected_files (list of {path,relevance,reasons}),
# - suggested_patch (a unified-diff combining all file changes, prefer minimal edits),
# - test_plan (list), risk, confidence.
# The suggested_patch should be directly usable by 'git apply' where possible.
GENERATE_DOC_PROMPT = (
"Produce a single JSON object with the following fields: "
"'title' (string), 'summary' (<=120 chars), 'affected_files' "
"(array of {path: str, relevance: 0.0-1.0, reasons: [str]}), "
"'suggested_patch' (string; unified-diff preferred), 'test_plan' (list of strings), "
"'risk' ('low'|'medium'|'high'), and 'confidence' (0-1 float). "
"The 'suggested_patch' must be minimal and formatted as a unified-diff when possible. "
"Return only the JSON object."
)
# Template for asking the LLM to select files from a rendered file-tree. The
# `{tree}` placeholder is replaced with the textual tree when calling the LLM.
# The model must internally rank candidates but output ONLY a JSON array of
# relative file paths (strings) sorted by descending relevance. Limit results
# to the top N (default 10) files. No extra text.
SELECTION_PROMPT_TEMPLATE = (
"Given the project file tree below, pick the top files most relevant to "
"fixing the issue. Internally rank candidates, but your final output MUST be "
"ONLY a JSON array of relative file paths (strings) in descending relevance order, "
"e.g. ['src/main.py','src/utils.py']. Return at most 10 paths and no extra text.\n\n{tree}\n"
)
# Template for summarization calls: inject a summarization prompt plus the
# concatenated file contents into `{doc_prompt}` and `{files}` respectively.
# The summarizer MUST return a single JSON object following the structure
# described in SUMMARIZE_DOC_PROMPT (per-file entries with suggested_patch strings).
SUMMARIZE_PROMPT_TEMPLATE = (
"{doc_prompt}\n\nFILES:\n{files}\n\n"
"Return a single valid JSON object as specified by the summarization prompt. "
"Do not add any extra commentary."
)
# EVOLVE-BLOCK-END
最も顕著な変更点は出力フォーマットの洗練です。単なる自由テキストではなく、リスクや affected_files のような補助タグが出力に追加されました。これらの変更は、ワークフローのコードを変更せずにステージ間のデータフローをプロンプトだけで変えられる可能性を示しています。はい、プロンプトだけでステージ間に流れるデータを変えられます。
しかし、それが何を意味するのか?良い質問です。進化は計算資源をますます消費し、進化させる要素が増えると予測不能になります。もしプロンプトのみを進化させるだけでデータフロー全体が改善され得ることを立証できれば、ターゲットを限定して安定性を向上させることができます。これは特に実データが見えない場合に重要です。
もう一つの顕著な変化は、パスのようなプロジェクト関連情報が出力に追加されたことです。これは簡単な推測で、実データにアクセスできるなら誰もが最初にやることです。
この実験は予備的であり、より多くのリポジトリでの追加実験が必要です。
実装についてもう少し詳しく
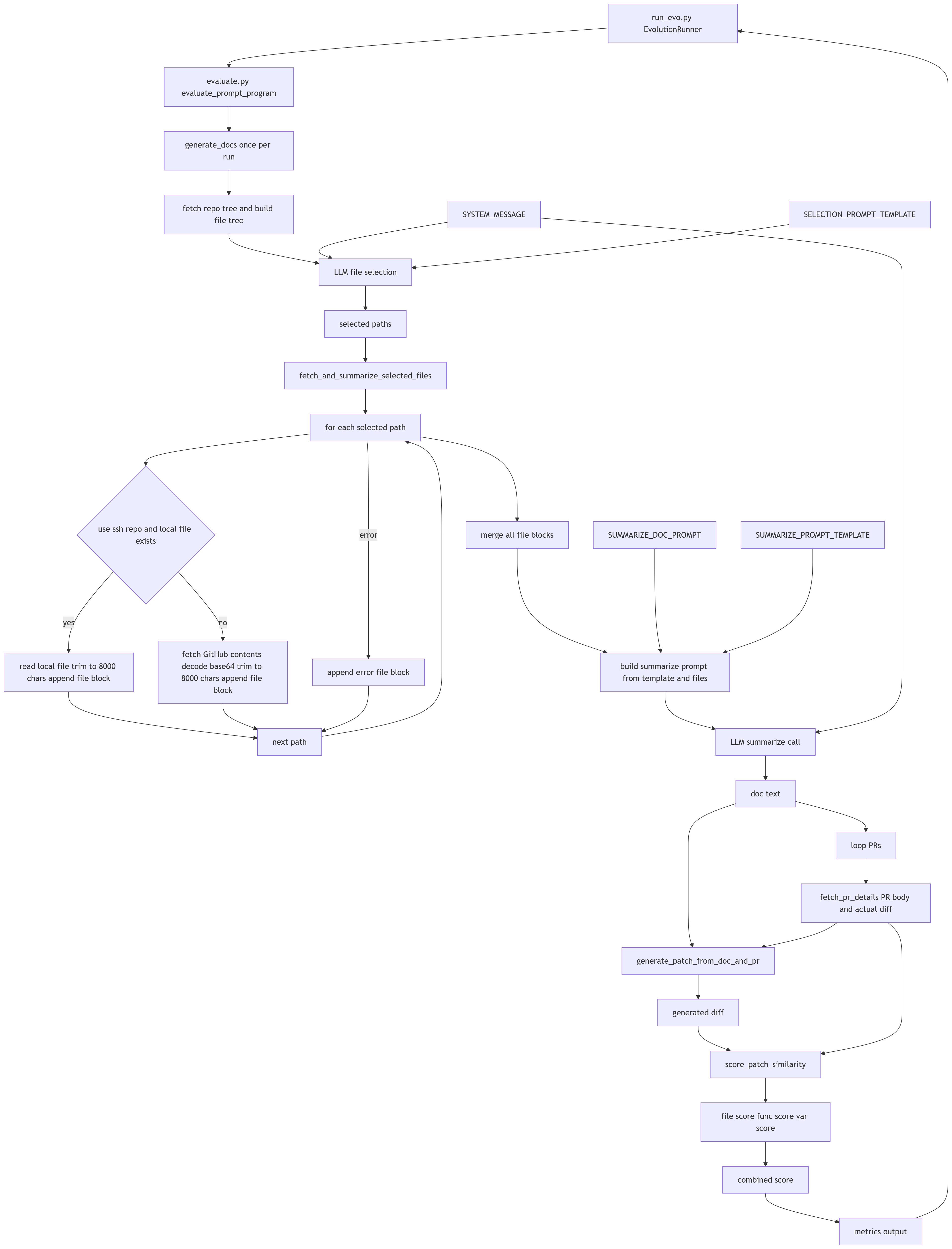
実験の実装は、ドキュメント生成ワークフロー、評価器(evaluator)、および ShinkaEvolve フレームワークに挿入された Copilot CLI アダプタで構成されています。
ドキュメント生成の主要なフローは examples/zed_doc_prompt/internal/docs_generator.py にあります。まずドキュメント生成に必要なファイルを特定し、その後ドキュメントを生成します。
評価器のコードは examples/zed_doc_prompt/evaluate.py にあります。GitHub から PR を取得し、PR に基づいてドキュメントを生成し、生成されたドキュメントに基づいてパッチを生成します。パッチを得たあと、評価器は実際にマージされたパッチとの類似度を計算します。
Copilot CLI プラグインは、ShinkaEvolve フレームワークが LLM API の代わりに Copilot CLI に LLM リクエストを渡せるようにします。Copilot CLI は純粋な推論用 LLM API が提供しないエージェントモードを埋め込みます。企業で Copilot プランを利用している場合、このプラグインはエージェントモードのギャップを埋めるのに有用かもしれません。
ShinkaEvolve 自体に関心がある場合は、こちらを参照してください: https://github.com/SakanaAI/ShinkaEvolve
もちろん、GitHub から取得した PR のキャッシングやその他の諸雑用といった細部は省略しています。詳細は examples/zed_doc_prompt/internal を確認してください。理解を深めるためのシステムアーキテクチャ図も用意されています。