Tuning Prompts Without Seeing Input or Output
- Al Roborol
- Fun , Insight
- October 28, 2025
Table of Contents
Is It Possible to Tune Prompts Without Seeing the Input and Output?
Tuning prompts without knowing input and output may sounds as silly as writing down the right answer without knowing the question.
I also doubt the necessity until I’m in a situation where all teams in an business unit store their data in their very own vaults. Those data are not even accessible to other teams in the same business unit. Creating AI workflows and apps there is exactly answering without seeing the question. And organizations like this one are common in manufacturing industry like automobiles.
Data Are Closed, but Goals Are Open
Luckily, manufacturing industry has common open goals when data are closed. Those goals can be inventory turns in SCM, mean time to repair in operation, Tact time in manufacturing and time-to-market in R&D.
These common goals makes it possible to apply reinforcement learning to the manufacturing industry without seeing the data. RL consists of a polocy model, a goal and a gym. Gim is the world the AI lives in and interact with. A polocy model keeps interacting with the gym to learn the best strategy to reach the goal. The training ends when the polocy model finds the best way to reach the goal in the gym. The internal of the gym is hidden throuhout the full training and only the minimal observables are exposed.
This is exactly the solution for manufacturing industry. The internal data is the internal of the gym (the world for AI to learn about). It can remain hidden all the time as long as proper observables and goals are available. And those goals are open and universal.
How to Actually Do This
Let’s take the familiar software development in manufacturing industry for example. Generating documents using AI is also needed there. The only difference is that code to generate documents from is hidden.
Let’s start with defining the goal. There are many possible goals for documents generation, especially when enterprises have different strategies. It’s hard to give the right answer. For simplicity, let’s make ‘if the documents can help fixing bugs’ the goal. Not a bad one, right?
Now comes the gym.
Since we don’t know about the data, we can’t make assumptions on the data structure. But data need to be stored somewhere and GitHub is often a choice. (Or at least Git.) In most cases, assuming pull requests are used to review and merge code won’t be too far away from the facts. I will assume the GitHub APIs for retrieving PRs are available. Of course, in actual cases this may not always be true so dig more with the clients before starting.
To make the PRs a gym, we need to define the possible interaction with the data and the observable output. Programmers interact with code via submitting patches (code modification) and this in a good interaction interface. Considering the PRs are verified modifications, the similarity between the actual patch in the PR and the generated patch is a good output.
Finally comes the last step: training. This can be a big topic. Trust me, you don’t want to go through the mathematics on finding the optimals in discrete spaces involving high dimensional embeddings. To be short, I recommend using the ShinkaEvolve to do the training. It uses mutation to generate candidate polocies robustly and efficiently and lock down the best one in a evolution-like filtering. Survival of the fittest.
Does It Really Work?
I don’t believe anything sound too good to be true. But this is true.
I ran a simple test on an open repository containing original design and got the patch similarity score with and without the documents generated by the RL model. The repository is https://github.com/pallets/click.
The model behind this experiement is gpt-5-mini behind Copilot CLI with agent mode enabled. Probably it’s the same model and tool you are using right now.
The score raised from 0.117 to 0.450. The accuracy increased 4 times.
The score has 3 normalized components, each from 0 to 1:
- file_score: exact per-file hunk-list match across the union of touched paths (strict, order-sensitive).
- func_score: Jaccard overlap of modified function names extracted from hunks.
- var_score: Jaccard overlap of modified variable/assignment names extracted from hunks.
Final weighted combination is:
combined=0.5 * file_score + 0.35 * func_score + 0.15 * var_score
Here is the full code if you want to try it out: https://github.com/alroborol/ShinkaEvolve-DocAgent
What Does the Experiment Do?
As mentioned before, the experiement tries to build an AI to create documents without seeing the code. The document are considered good if it helps to fix the bugs better.
The evaluation is done with only 3 seleced PRs from the repository due to comptation resource limitation.
To be specific the AI to be tuned are four prompts in an document generation AI workflow. One is the universal prompt and the other three are the prompts for each process in the workflow.
Here are the actually initial prompts before evolution:
# EVOLVE-BLOCK-START
# System-level instruction: sent as the `system_msg` to the LLM client to
# establish role and global expectations for all queries in this module.
SYSTEM_MESSAGE = (
" "
)
# Summarization prompt: used to create concise, developer-facing documentation
# geared toward code review, focusing on purpose, APIs, error handling and edge
# cases. Use when summarizing selected files.
SUMMARIZE_DOC_PROMPT = (
"Summarize the document"
)
# Template for asking the LLM to select files from a rendered file-tree. The
# `{tree}` placeholder is replaced with the textual tree when calling the LLM.
SELECTION_PROMPT_TEMPLATE = (
"Given the project file tree below, pick files to check."
"eply ONLY with a JSON array of the "
"relative file paths you choose (no extra text).\n\n{tree}\n"
)
# Template for summarization calls: inject a summarization prompt plus the
# concatenated file contents into `{doc_prompt}` and `{files}` respectively.
SUMMARIZE_PROMPT_TEMPLATE = (
"{doc_prompt}\n\n{files}"
)
# EVOLVE-BLOCK-END
Can’t wait to see the final prompts? Here they are:
# EVOLVE-BLOCK-START
# System-level instruction: sent as the `system_msg` to the LLM client to
# establish role and global expectations for all queries in this module.
# Strongly prefer machine-parseable outputs (JSON/unified-diff) and minimal,
# human-like edits that can be applied as patches. Do NOT include freeform
# commentary outside the required structured output.
SYSTEM_MESSAGE = (
"You are an expert software maintainer and reviewer. Produce concise, "
"patch-oriented developer documentation that directly supports creating and "
"applying fixes. Always return only the structured output requested by the "
"prompt (see below) with no extra explanation. Favor unified-diff snippets "
"for code edits, include clear tests-to-add, and provide short 'risk' and "
"'confidence' fields so downstream tooling can prioritize changes."
)
# Prompt used to create concise, developer-facing documentation geared toward
# producing fixes: the output MUST be valid JSON. For single-file summaries
# return an object; for multiple files return a single JSON object containing
# per-file entries. Each per-file entry should include:
# - path: relative file path
# - short_description: 1-2 sentence diagnosis
# - suggested_patch: unified-diff string OR a minimal step list (prefer diff)
# - tests: list of one-line test suggestions
# - risk: 'low'|'medium'|'high'
# - confidence: float between 0 and 1
SUMMARIZE_DOC_PROMPT = (
"Summarize the document(s) into a JSON object. For each file include: "
"path, short_description (1-2 sentences), suggested_patch (unified-diff preferred), "
"tests (list of one-line suggestions), risk ('low'|'medium'|'high'), and "
"confidence (0-1). Output must be valid JSON and nothing else."
)
# Top-level prompt used to request generation of docs + patches. The model MUST
# return a single JSON object with fields:
# - title, summary (<=120 chars), affected_files (list of {path,relevance,reasons}),
# - suggested_patch (a unified-diff combining all file changes, prefer minimal edits),
# - test_plan (list), risk, confidence.
# The suggested_patch should be directly usable by 'git apply' where possible.
GENERATE_DOC_PROMPT = (
"Produce a single JSON object with the following fields: "
"'title' (string), 'summary' (<=120 chars), 'affected_files' "
"(array of {path: str, relevance: 0.0-1.0, reasons: [str]}), "
"'suggested_patch' (string; unified-diff preferred), 'test_plan' (list of strings), "
"'risk' ('low'|'medium'|'high'), and 'confidence' (0-1 float). "
"The 'suggested_patch' must be minimal and formatted as a unified-diff when possible. "
"Return only the JSON object."
)
# Template for asking the LLM to select files from a rendered file-tree. The
# `{tree}` placeholder is replaced with the textual tree when calling the LLM.
# The model must internally rank candidates but output ONLY a JSON array of
# relative file paths (strings) sorted by descending relevance. Limit results
# to the top N (default 10) files. No extra text.
SELECTION_PROMPT_TEMPLATE = (
"Given the project file tree below, pick the top files most relevant to "
"fixing the issue. Internally rank candidates, but your final output MUST be "
"ONLY a JSON array of relative file paths (strings) in descending relevance order, "
"e.g. ['src/main.py','src/utils.py']. Return at most 10 paths and no extra text.\n\n{tree}\n"
)
# Template for summarization calls: inject a summarization prompt plus the
# concatenated file contents into `{doc_prompt}` and `{files}` respectively.
# The summarizer MUST return a single JSON object following the structure
# described in SUMMARIZE_DOC_PROMPT (per-file entries with suggested_patch strings).
SUMMARIZE_PROMPT_TEMPLATE = (
"{doc_prompt}\n\nFILES:\n{files}\n\n"
"Return a single valid JSON object as specified by the summarization prompt. "
"Do not add any extra commentary."
)
# EVOLVE-BLOCK-END
The most noticebale changes are the refining of the output format. Instead of pure text, auxilary tags like risks and affected_files are added into the output. These changes show the possibility of modifying the data flow between stages without changing the workflow code. Yes, prompts only can change what data flows between stages.
But so what? Good question. The evolution takes more and more computation resources and goes unpredictable when the evolving elements increase. If we can prove evolving only prompts can still improving the whole data flow, we can confidently limit the targets and improve the stability. This is especially improtant when we can’t see the actual data.
Another noticebale change is project related information like paths are added. That’s a easy guess. That is what everyone would do firstly, when they can access the real data.
This experiement is prelimitary and require further experiement on more repositories.
Tell Me More About the Implementation
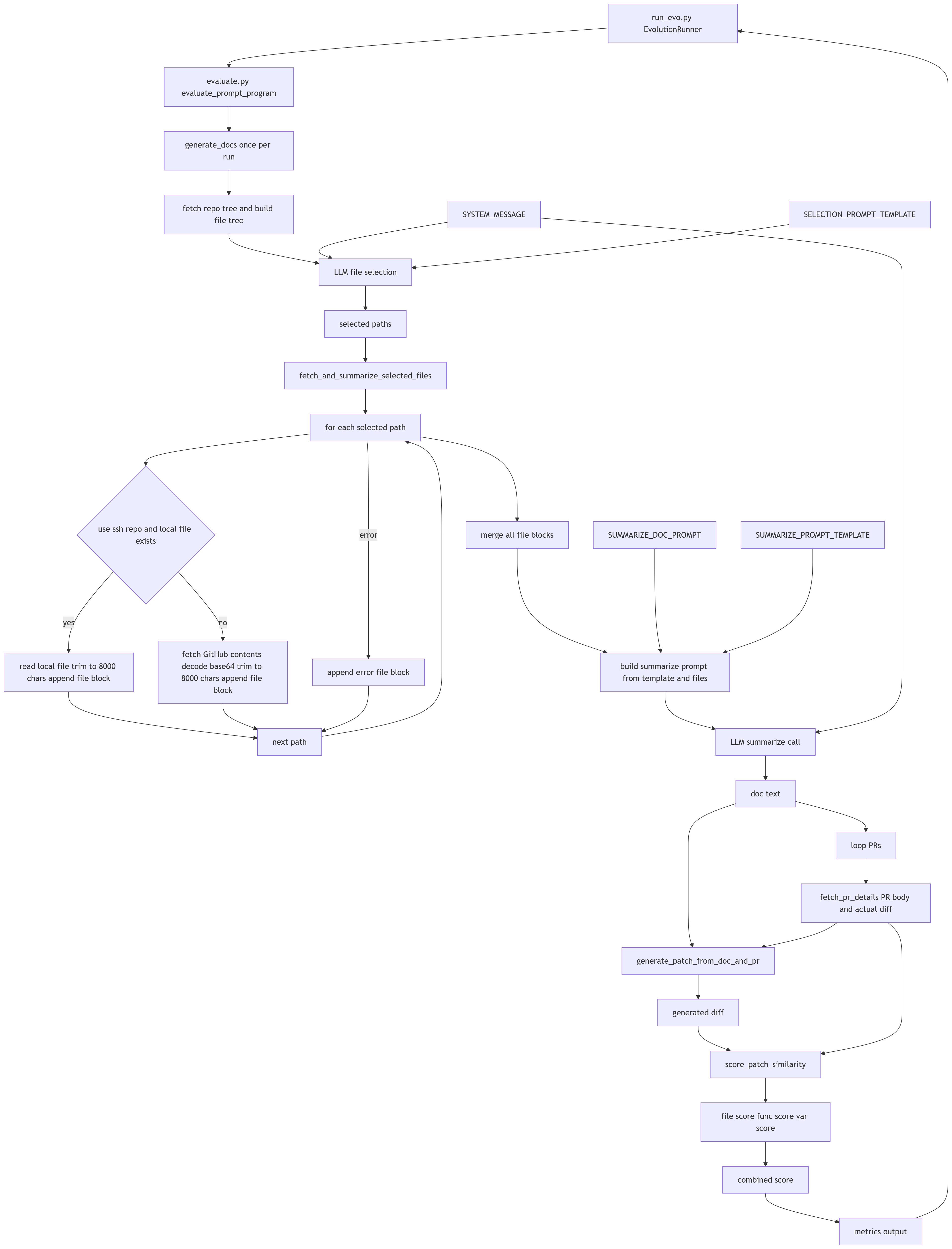
The experiement implementation consists of a document generation workflow, an evaluator and a Copilot CLI adapter inserted into the ShinkaEvolve framework.
The document generation main flow can be found in examples/zed_doc_prompt/internal/docs_generator.py. First it tries to find what files are necessary to generate the document. Then it generates the documents.
The evaluator code is in examples/zed_doc_prompt/evaluate.py. It fetches PRs from github, generate document based on the PR and generate patch based on the PR request and document generated. After getting the patch, evaluator calculates the similarity against the actually merged patch.
The Copilot CLI plugin enables ShinkaEvolve framework to pass LLM requests to Copilot CLI instead of LLM APIs. Copilot CLI embebs agent mode inside that pure inference LLM API doesn’t provide. This plugin may be useful to you to close the agent mode gap if you work in enterprises with Copilot plans.
If you want to know about the ShinkaEvolve too, check their github: https://github.com/SakanaAI/ShinkaEvolve.
Of course, details like caching PRs retrieved from GitHub and other chores are omitted. You can check them here: examples/zed_doc_prompt/internal. And here is the system architecture diagram to help you dig more.